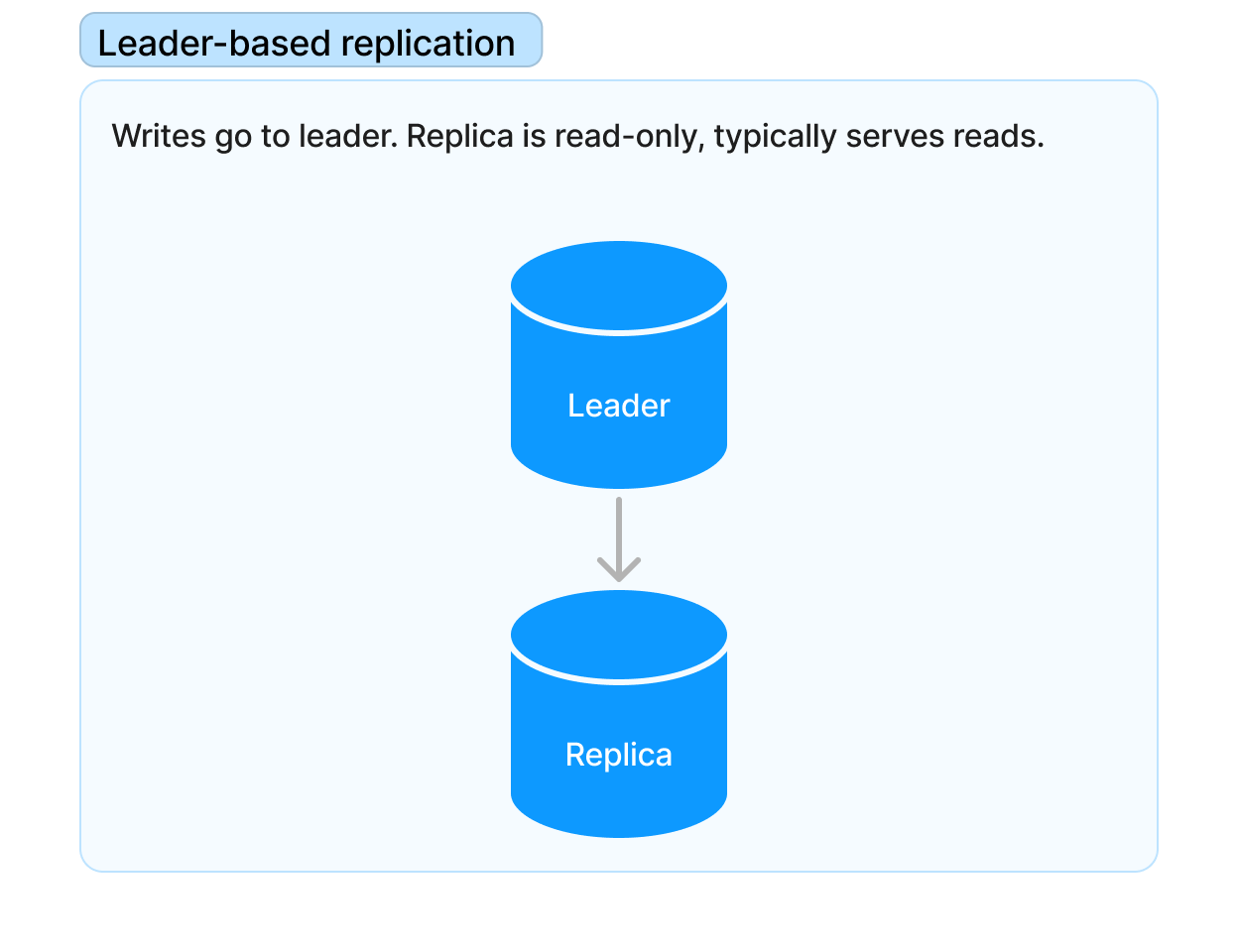
Leader-based replication
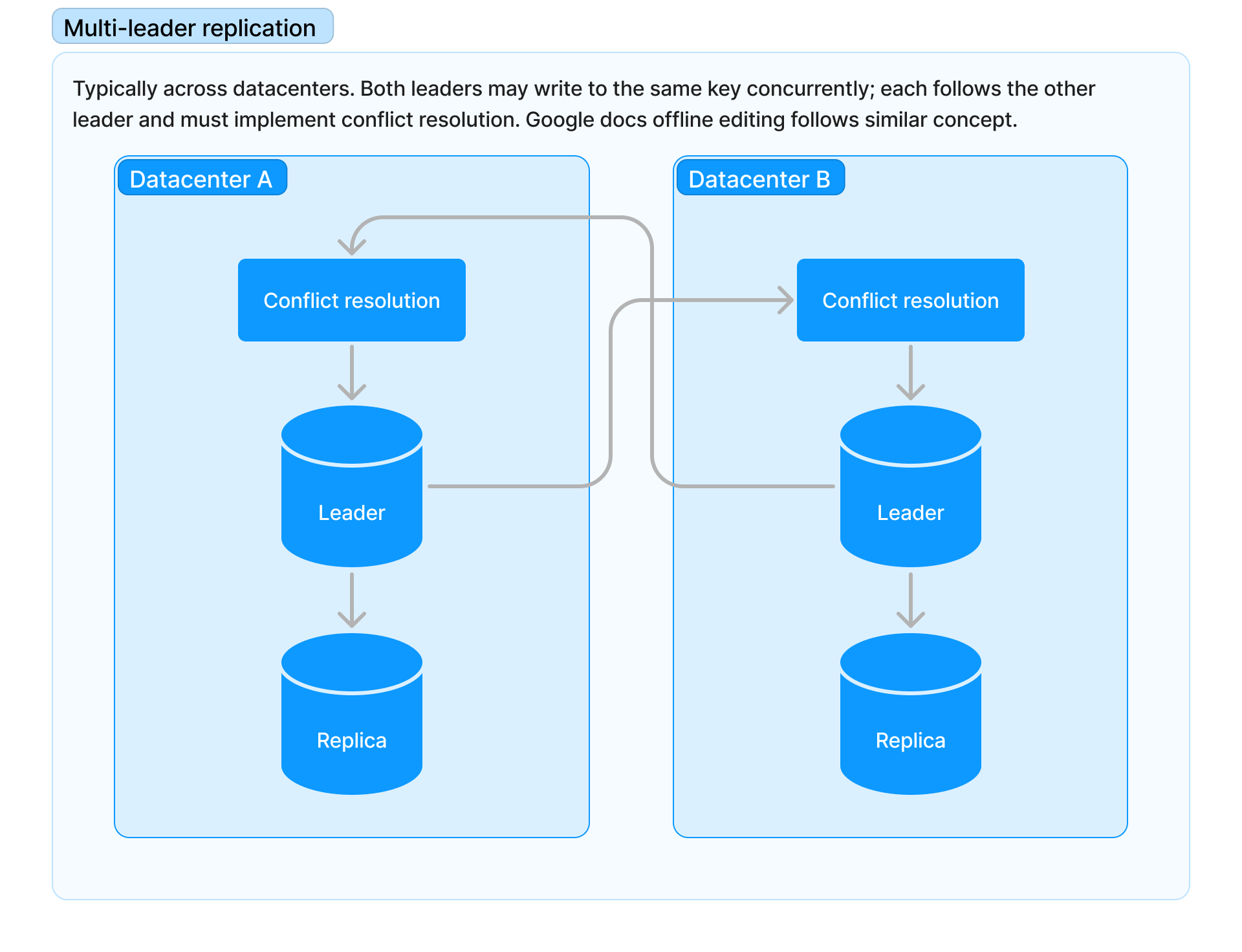
Multi-leader replication (active-active)
Leaderless replication
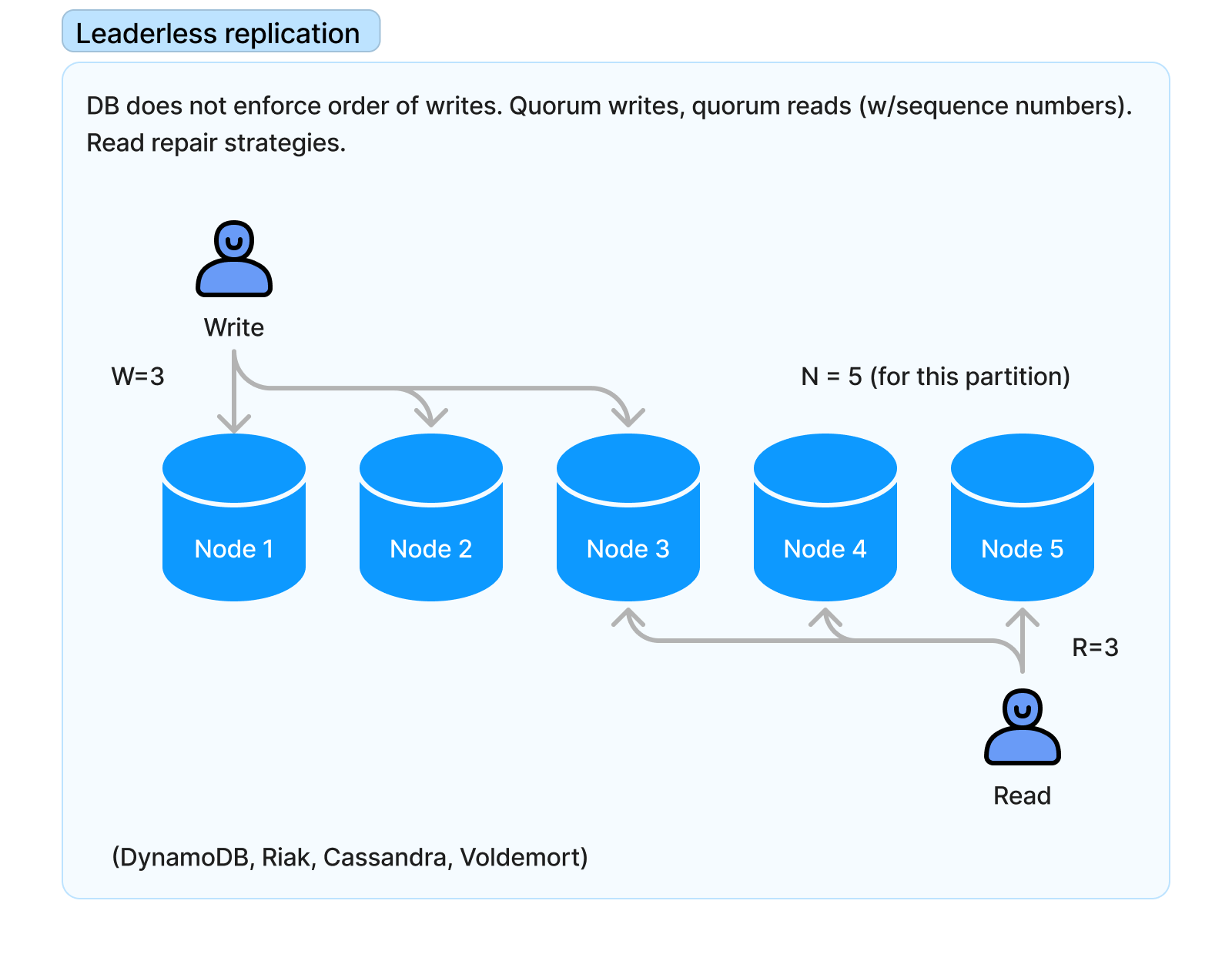
- Even with
R + W > N, don’t assume guarantee, e.g. what if a node with the write goes offline and another is added with an outdated value? - Consistency suffers (even more with sloppy quorums), but: scalability, fault-tolerance even to datacenter failures, tolerates latency spikes & network interruptions.
Concurrent writes resolution strategy
👀 because clocks cannot be trusted, concurrent writes that don’t know about each other HAVE NO ORDER.
- Last Write Wins (timestamp): sloppy, because clocks cannot be trusted.
- Sequence numbers / version-vectors define the “happens-before” relationship.
- Let application resolve conflict by providing all versions of concurrent writes.
Leaderless guarantees
(from DDIA)
“In particular, you usually do not get the guarantees discussed in “Problems with Replication Lag” (reading your writes, monotonic reads, or consistent prefix reads), so the previously mentioned anomalies can occur in applications. Stronger guarantees generally require transactions or consensus.”
If leaderless so problematic for consistency, why recommended for chat?
- In practice, they don’t use it! Check here what they use.
- Total order (i.e. linearizability) is required for chat, so it’s usually implemented as sequence numbers in the application layer.
- Cassandra/HBase offer availability, scalability, durability/reliability, so at least they make sense for long-term storage.