(not a guide for this question; only for how this question is different from all others)
Main specific discussion points
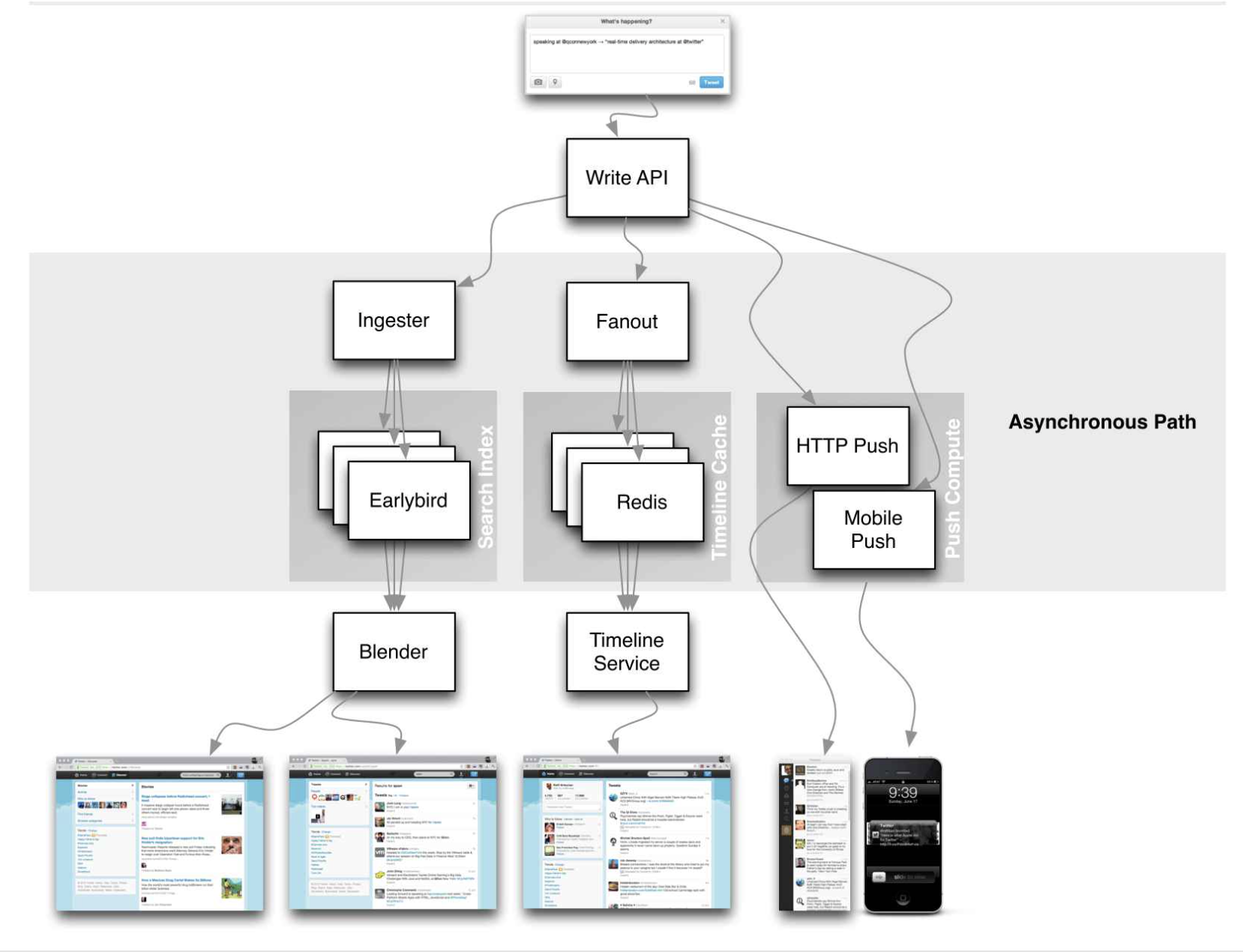
- Timeline cannot be computed on read: 🧠 start by showing with estimations & requirements that it wouldn’t scale.
- Social graph: RDBMS table to keep track of who follows who, cached for min latency. 🧠 Show difference in latency cache vs RDBMS
SELECT. - Search: use Lucene to tag documents on write. On search, all search shards must be queried. Why?
- Active/passive users/Celebrities get different treatment: precalculate timelines, fan-out vs multi-get on read.
- When discussing timeline, talk about post-processing: filtering the precalculated timeline.
- Optional: Write path has mostly pull but potentially push model in case of push notifications.
What does Twitter use?
- Storing tweets: Manhattan, in-house eventually consistent database (with strong-consistency for some workloads), with 3 storage backends: read-only for Hadoop data, LSM tree for high-write, BTree for high-read/low-write. Low-level storage is Apache BookKeeper. It started with MySQL, then built a MySQL clustering solution, then Manhattan.
- Caching tweets: Memcached.
- Caching timelines: Redis.
- Provisioning IDs: Snowflake.