Building Crypto Predictions Tracker: architecture and challenges

TL;DR
During the past year I’ve gotten exposure to the cryptocurrency scene from an investment perspective. A key frustrating aspect of it is that there’s no reliable source of investment advice. I describe this problem in detail on my previous blogpost: Cryptocurrency influencers are preying on millennials who found salvation in crypto.
I’ve been working on a Go-based project to automatically track cryptocurrency predictions made on social networks like this one for the last 6 months, as a tool for accountability and influencer reputation. I think the resulting system ended up being pretty neat and it might interest you if you’re a backend engineer. In this blogpost, I’ll define this system and describe its architecture.
The backend system is available here: Crypto Predictions Tracker.
A frontend to this project is this Twitter account: Crypto Predictions Tracker.
A key component of building this project was to consume cryptocurrency market data provided by exchanges. I’ve open sourced a library that facilitates this task in a simple and efficient manner. The crypto-candles library is available on Github and its construction and features are described on my blogpost: 10 Gotchas for building a universal crypto candlestick iterator in Go.
Motivation
A fundamental problem of available cryptocurrency-related investment advice on the Internet is that there is no track-record anywhere. Consider other businesses:
Before making a hotel or restaurant booking, we can check their rating online on our phones.
Before making a decision on a rental flat or buying a house, we can compare neighbourhood prices and do inspections.
Before choosing an investment fund, we can check comparison studies as well as the historical ROI of the chosen fund itself.
Now consider examples of advice given by cryptocurrency influencers, like this one:
I’m hoping most of you reading this right now will be thinking: “why would anyone in their right mind follow the investment advice of some dude on the Internet?”. I think so too. However, some of these influencers have more than a million followers! I think it’s fair to assume that advice is being followed galore. For a more exhaustive read of this problem, please read my blogpost: Cryptocurrency influencers are preying on millennials who found salvation in crypto.
I don’t think all advice is malintentioned, and even if it was, I don’t think it should be banned or made illegal, the same way that I don’t think smoking, drinking and drugs should be illegal either. However, some form of warning should be available for them, the same way that there are warnings on cigarette packs and ratings on restaurants and hotels. Then, influencers would have a track-record that keeps them honest, and individuals can make informed decisions. But is that possible?

Key Insights on feasibility
Note how social network posts are particularly well-suited for keeping a track record:
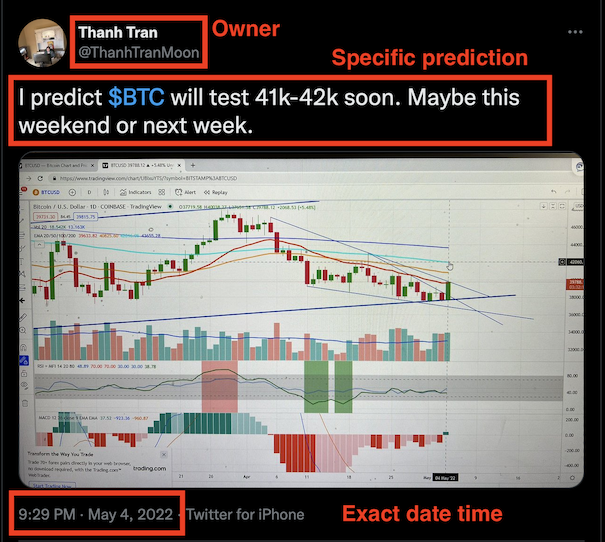
They have:
a date
an owner
mostly reasonably un-editable content
Provided that the content is specific enough, as in the above example, then one could manually go to the exchange’s website every now and then and check the market pair’s last value against the prediction. In most cases, it’s important that the prediction has some deadline: otherwise either we could be checking forever, and besides there’s little value on a prediction that can only become true eventually, but never times out and becomes false.
If this can be done manually, can it be automated?
Yes! All exchanges (mostly) provide free APIs to consume current and historical market pair data. Social networks also have free APIs to consume public post metadata (thank you Twitter & Reddit).
Automating the system
At a high level, automating tracking for one prediction looks like this:
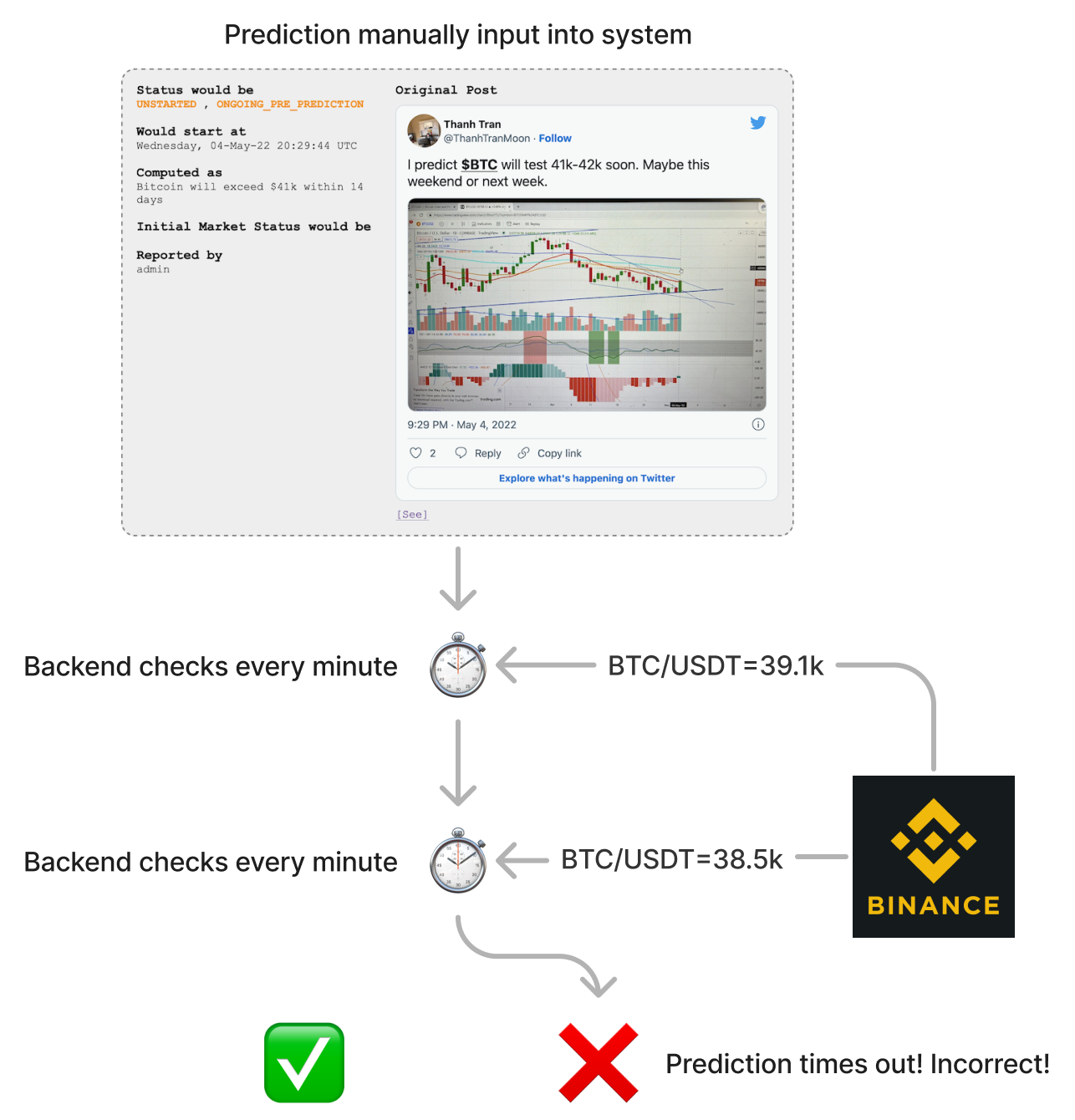
Manually input the prediction metadata (e.g. who predicts, which market pair, by when, prediction condition) as an object/struct in memory.
Every minute or so, ask the exchange for the current last price of the market pair.
Upon receiving the new price, check if the prediction condition was met.
If condition met, prediction became true!
If condition stays false until deadline, prediction became false!
A million caveats
While the above looks very simple, every bullet point is trickier than it looks, even before introducing architectural considerations.
Here are some illustrative examples:
A prediction should ideally specify which exchange it is for. There is no one value for a given market pair, that is, the last price of Bitcoin against Tether can differ between the Binance exchange and the Coinbase exchange at the same timestamp, because the last price is defined by the order book, and different exchanges have different order books! This causes two problems: (1) this system must implement ALL exchange APIs, and (2) predictions that don’t specify exchange cannot really be tracked accurately, although in practice some assumptions are reasonable.
Social networks don’t reveal the timezone of post authors, authors don’t specify which timezones they make their predictions for, and cryptocurrency influencers typically travel around a lot, so prediction deadlines are imprecise. The closer the deadline, the least precise is the tracking of the prediction.
In practice, >80% of predictions are surprisingly homogeneous and simple in structure, in the form: “Coin against Stablecoin will reach Value by Deadline”. But for some outliers, the discussed algorithm of a prediction being false until it becomes true or times out doesn’t work. For example, consider this one: “Ethereum won’t reach 3000 until December”.
It would be very lucky if the system would always catch fresh predictions made just now, but in practice the system will input predictions made some time in the past, so old predictions have to “catch up to the present” by checking the evolution of price since the start of the prediction timestamp, to now. The API endpoints for historical prices and current prices are separate.
The last price for a market pair changes with every filled order. On an exchange with a very high volume of transactions, several hundreds of orders could be filled every second. Checking the condition for every order would be the most accurate way to evaluate the prediction, because in theory there could be a very short period of very high price volatility in which the prediction briefly becomes true, and we might miss this fact in an averaged bucket of orders. In practice, this would be unfeasible, especially if we’re planning to do it for more than a single prediction.
Architectural building blocks
At a minimum, these components are going to be required:
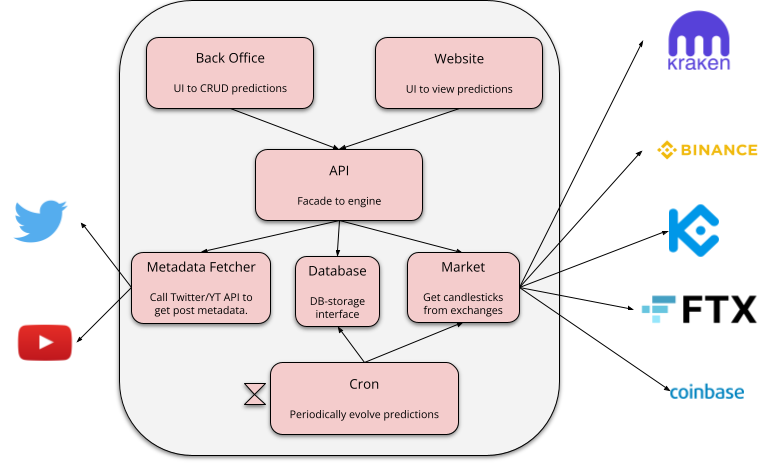
Database: each prediction contains some metadata (e.g. who, what, when) and some state (e.g. last recorded price and when, status of prediction). This data should survive restarts and evolve in atomic steps.
Market requester: predictions evolve upon evaluating market data, so the system needs a component that knows how to talk to all Exchange APIs.
Social Network requester: predictions are created upon consuming social network post metadata (e.g. who, what, when), so the system needs a component that can request post metadata from e.g. Twitter.
Back Office: a minimal frontend to CRUD predictions, and to see what happens to them.
Cron: a process that will evolve active predictions at regular intervals, with the newest market data.
If we want the system to be useful to a larger population than just its creator, two extra components become relevant:
Frontend: some UI to display the information created, like a website. It could also be some report export function.
API: since now there are three components reading data (Cron, Back Office and Frontend), and potentially the Frontend could be consumed by untrusted clients, it becomes important to have a unified interface for managing access to that data.
Architectural challenges
Implementing support for arbitrary predictions
A prediction post can be as simple as “Bitcoin will be worth 100K in 2022!” which can be normalized (with some assumptions) to: “BTC against USDT (Tether) in the Binance exchange (spot market as opposed to some other derivatives market) will be greater than or equal to $100,000 within the post’s timestamp and the first second of Jan 1st, 2023”. That prediction cannot become false before end of year.
As it turns out, 80% or more of the predictions are as simple as that example. Considering the most popular cryptocurrency influencers, there are mostly only a few prediction patterns in total.
Sometimes, an influencer will make their “next run predictions” like so:

If we want to support that, we need to add boolean operator support over the initial implementation.
It’s quite common to see a pattern of “If a cryptocurrency falls below X, it will go all the way down to Y”. For example:

This prediction has two steps: a “prerequisite” which “enables” the prediction, and the prediction itself. If the “prerequisite” is not met, then the prediction is not false but “annulled”. Often, these predictions cannot be input because they lack specific deadlines.
Finally, some predictions become true if a condition is true until a deadline, like this one:
This prediction breaks the model in which a prediction is false unless it becomes true before some deadline.
There are more edge cases, but they are less common, so I won’t mention them here. I’ve implemented support for many of these patterns and others, and in my experience the problem is not at all the coding & testing involved: the real issue is the UI for inputting and for showing the status of predictions. Rather than providing so much flexibility, it works a lot better to offer a few pre-baked templates, and enable UI support for those.
Requesting market data
Predictions posted online tend to follow market trends, so the most popular cryptocurrencies get the most predictions, somewhat following the 80/20 Pareto principle. This means that, if we have 100 predictions and we evolve them every minute, we’re gonna be making a lot of identical requests to the exchange’s APIs. This is not just very inefficient but also unlikely to last long, because as the number of predictions grow, very soon the exchange’s APIs will ban our IPs and ask us to enhance our calm.
The simplest solution to this problem is to cache market responses. In theory, this makes perfect sense, since one wouldn’t expect historical market data to change. In practice, this is almost true, but one should be careful to consider some received data point “final”, since very recent data might be “still getting aggregated”, and exchanges do not clarify if a data point is final or not. A mitigation is to not consume very recent data points.
Note that the caching component is very valuable, but in a very small window of time. It’s not common to need to request old data, because most predictions are about future deadlines. Thus, it’s not necessary to build a full-fledged solution for caching.
Storing predictions and evolving them
Predictions are esentially state machines, and they have two parts: metadata (e.g. author, deadline, conditions), and state (e.g. last timestamp requested for each market pair, status of condition(s) that compose the prediction).
Only the state part evolves over time. On each evolution step, one needs to request the latest data points for the involved market pairs, re-evaluate the prediction condition(s) and possibly change the status of it to “correct”/“incorrect”.
Further, out of the database of predictions, only a subset evolves: the active predictions. However, the state part of all active predictions must be updated every time. This write pattern suggests using some in-memory layer before reaching the durable store to alleviate disk pressure and latency, although then if someone kicks the power cable progress is lost.
Of course, for a small project that is just starting up and where cost is a major concern, a batch update statement on a small Postgres instance is more than enough. In order to set up the project for growth, we can just hide the storage layer implementation details behind a simple interface.
Predictions tend to have a common deadline
End of year, end of month, or whenever a big event will take place (e.g. whenever the CPI is going to be announced, whenever the halving happens) are very common instants for predictions. This is absolutely fine in terms of evolving the predictions, but if one plans to trigger some actions like sending out notifications, instant hotspots could be problematic.
Possible mitigations are to buffer and aggregate notifications, or to cap the amount of notifications that can be sent in a given time period.
Takeaways from tracking predictions for the last few months
A key criticism for this project is that it is pointless to track what influencers say, because no one in their right mind should take their advice when they make their investment decisions. If you share this point of view (like me!), wouldn’t it be useful to be able to answer how often predictions become correct?
How often do predictions become correct?
Well, thanks to this project, I can answer that! Results have caveats (e.g. some influencers make more specific predictions than others, averaging results compares apples & oranges because some predictions are bolder than others), but they are definitely not meaningless. Insights will be vague, because the sample is less than a thousand predictions, and it simply hasn’t been that long since I started tracking them.
Here are the takeaways:
Predictions become correct reliably about 25% of the time.
Deadline matters: prediction correctness drops to 20% when deadline is 4 days or less in the future or more than a month, sweet spot being about two weeks.
80% of all predictions are made for a deadline earlier than or equal to a month in the future.
Some influencers are definitely more reliable than others.
I don’t want to be thought of as endorsing influencers and I also don’t want to talk without sufficient data, but I can say preliminarly that you should probably ignore specific predictions given by:
- rovercrc
- trader1sz
- profit8lue
And you could listen to (but don’t delegate your financial decisions!!!) specific predictions given by:
- CryptoCapo_
- IncomeSharks
- CredibleCrypto
There are plenty of others, but either they make vague predictions or don’t make enough to make statistically significant conclusions (in a 6 month timeframe).
Is there any more value out of this project?
Evidently, the current state of this project is of little relevance to people. Otherwise, the Twitter account would have more followers and my blogs about it would generate more buzz. Personally, I think anyone following a crypto influencer with the intention of following their advice can only benefit from an impartial, automated track-record for them, but this thought-process makes the assumption that human decisions always makes sense. This has been refuted, and it is really confusing to me.
However, in order to take this project to production I had to build many components that could be used or adapted for other interesting uses.
Evaluating paid subscriptions that offer “cryptocurrency signals”
Many individuals or anonymous companies offer a monthly subscription of “cryptocurrency signals”, which are esentially specific predictions. Those services routinely claim that 80%+ of their signals are profitable.
The only difference between signals and predictions is that signals are not “boolean”, in that they are not “Correct” or “Incorrect”, but instead they have a Profit Margin Ratio, that is, if you action them, you earn or lose a percentage of your investment.
Nobody has ever done a reliable, transparent evaluation of a Cryptocurrency Signal site. It would be too tricky to build the infrastructure necessary to run it. With the tools I’ve built, it would be very simple to do this.
Building datasets for data science experiments
If you’ve ever reviewed any articles that do research based on market data, you’ll quickly realise that it’s very rare to see any research aggregating data from different exchanges. There is Messari, but I initially implemented it and ended up scrapping it, as I couldn’t get reliable results.
The library I open sourced for reading market data, crypto-candles, is very efficient and has a very simple interface (it builds iterators), so I think it would be ideal for getting data for experiments.
In general, while there are very good freemium UIs for cryptocurrency data, most notably TradingView, there isn’t any good free API for getting market data across exchanges. crypto-candles solves this issue as a library you can import, or a CLI you can call.
Conclusion
I think that Crypto Predictions Tracker was a useful, free warning service for people thinking about following the advice of cryptocurrency influencers. But even if it’s not, I really enjoyed building its backend.
Unfortunately, Heroku shut down the dynos I was using to power the cron and the API (switched to Render which has a free plan with DB & Cron), and Twitter restricted their API access, so it got too cumbersome to support it. I think there’s value that can be repurposed in an eventual iteration.
Thanks for reading, and I hope you can benefit from the tools and services I created. Good luck!
TL;DR
During the past year I’ve gotten exposure to the cryptocurrency scene from an investment perspective. A key frustrating aspect of it is that there’s no reliable source of investment advice. I describe this problem in detail on my previous blogpost: Cryptocurrency influencers are preying on millennials who found salvation in crypto.
I’ve been working on a Go-based project to automatically track cryptocurrency predictions made on social networks like this one for the last 6 months, as a tool for accountability and influencer reputation. I think the resulting system ended up being pretty neat and it might interest you if you’re a backend engineer. In this blogpost, I’ll define this system and describe its architecture.
The backend system is available here: Crypto Predictions Tracker.
A frontend to this project is this Twitter account: Crypto Predictions Tracker.
A key component of building this project was to consume cryptocurrency market data provided by exchanges. I’ve open sourced a library that facilitates this task in a simple and efficient manner. The crypto-candles library is available on Github and its construction and features are described on my blogpost: 10 Gotchas for building a universal crypto candlestick iterator in Go.
Motivation
A fundamental problem of available cryptocurrency-related investment advice on the Internet is that there is no track-record anywhere. Consider other businesses:
Before making a hotel or restaurant booking, we can check their rating online on our phones.
Before making a decision on a rental flat or buying a house, we can compare neighbourhood prices and do inspections.
Before choosing an investment fund, we can check comparison studies as well as the historical ROI of the chosen fund itself.
Now consider examples of advice given by cryptocurrency influencers, like this one:
I’m hoping most of you reading this right now will be thinking: “why would anyone in their right mind follow the investment advice of some dude on the Internet?”. I think so too. However, some of these influencers have more than a million followers! I think it’s fair to assume that advice is being followed galore. For a more exhaustive read of this problem, please read my blogpost: Cryptocurrency influencers are preying on millennials who found salvation in crypto.
I don’t think all advice is malintentioned, and even if it was, I don’t think it should be banned or made illegal, the same way that I don’t think smoking, drinking and drugs should be illegal either. However, some form of warning should be available for them, the same way that there are warnings on cigarette packs and ratings on restaurants and hotels. Then, influencers would have a track-record that keeps them honest, and individuals can make informed decisions. But is that possible?
Key Insights on feasibility
Note how social network posts are particularly well-suited for keeping a track record:
They have:
a date
an owner
mostly reasonably un-editable content
Provided that the content is specific enough, as in the above example, then one could manually go to the exchange’s website every now and then and check the market pair’s last value against the prediction. In most cases, it’s important that the prediction has some deadline: otherwise either we could be checking forever, and besides there’s little value on a prediction that can only become true eventually, but never times out and becomes false.
If this can be done manually, can it be automated?
Yes! All exchanges (mostly) provide free APIs to consume current and historical market pair data. Social networks also have free APIs to consume public post metadata (thank you Twitter & Reddit).
Automating the system
At a high level, automating tracking for one prediction looks like this:
Manually input the prediction metadata (e.g. who predicts, which market pair, by when, prediction condition) as an object/struct in memory.
Every minute or so, ask the exchange for the current last price of the market pair.
Upon receiving the new price, check if the prediction condition was met.
If condition met, prediction became true!
If condition stays false until deadline, prediction became false!
A million caveats
While the above looks very simple, every bullet point is trickier than it looks, even before introducing architectural considerations.
Here are some illustrative examples:
A prediction should ideally specify which exchange it is for. There is no one value for a given market pair, that is, the last price of Bitcoin against Tether can differ between the Binance exchange and the Coinbase exchange at the same timestamp, because the last price is defined by the order book, and different exchanges have different order books! This causes two problems: (1) this system must implement ALL exchange APIs, and (2) predictions that don’t specify exchange cannot really be tracked accurately, although in practice some assumptions are reasonable.
Social networks don’t reveal the timezone of post authors, authors don’t specify which timezones they make their predictions for, and cryptocurrency influencers typically travel around a lot, so prediction deadlines are imprecise. The closer the deadline, the least precise is the tracking of the prediction.
In practice, >80% of predictions are surprisingly homogeneous and simple in structure, in the form: “Coin against Stablecoin will reach Value by Deadline”. But for some outliers, the discussed algorithm of a prediction being false until it becomes true or times out doesn’t work. For example, consider this one: “Ethereum won’t reach 3000 until December”.
It would be very lucky if the system would always catch fresh predictions made just now, but in practice the system will input predictions made some time in the past, so old predictions have to “catch up to the present” by checking the evolution of price since the start of the prediction timestamp, to now. The API endpoints for historical prices and current prices are separate.
The last price for a market pair changes with every filled order. On an exchange with a very high volume of transactions, several hundreds of orders could be filled every second. Checking the condition for every order would be the most accurate way to evaluate the prediction, because in theory there could be a very short period of very high price volatility in which the prediction briefly becomes true, and we might miss this fact in an averaged bucket of orders. In practice, this would be unfeasible, especially if we’re planning to do it for more than a single prediction.
Architectural building blocks
At a minimum, these components are going to be required:

Database: each prediction contains some metadata (e.g. who, what, when) and some state (e.g. last recorded price and when, status of prediction). This data should survive restarts and evolve in atomic steps.
Market requester: predictions evolve upon evaluating market data, so the system needs a component that knows how to talk to all Exchange APIs.
Social Network requester: predictions are created upon consuming social network post metadata (e.g. who, what, when), so the system needs a component that can request post metadata from e.g. Twitter.
Back Office: a minimal frontend to CRUD predictions, and to see what happens to them.
Cron: a process that will evolve active predictions at regular intervals, with the newest market data.
If we want the system to be useful to a larger population than just its creator, two extra components become relevant:
Frontend: some UI to display the information created, like a website. It could also be some report export function.
API: since now there are three components reading data (Cron, Back Office and Frontend), and potentially the Frontend could be consumed by untrusted clients, it becomes important to have a unified interface for managing access to that data.
Architectural challenges
Implementing support for arbitrary predictions
A prediction post can be as simple as “Bitcoin will be worth 100K in 2022!” which can be normalized (with some assumptions) to: “BTC against USDT (Tether) in the Binance exchange (spot market as opposed to some other derivatives market) will be greater than or equal to $100,000 within the post’s timestamp and the first second of Jan 1st, 2023”. That prediction cannot become false before end of year.
As it turns out, 80% or more of the predictions are as simple as that example. Considering the most popular cryptocurrency influencers, there are mostly only a few prediction patterns in total.
Sometimes, an influencer will make their “next run predictions” like so:
If we want to support that, we need to add boolean operator support over the initial implementation.
It’s quite common to see a pattern of “If a cryptocurrency falls below X, it will go all the way down to Y”. For example:
This prediction has two steps: a “prerequisite” which “enables” the prediction, and the prediction itself. If the “prerequisite” is not met, then the prediction is not false but “annulled”. Often, these predictions cannot be input because they lack specific deadlines.
Finally, some predictions become true if a condition is true until a deadline, like this one:
This prediction breaks the model in which a prediction is false unless it becomes true before some deadline.
There are more edge cases, but they are less common, so I won’t mention them here. I’ve implemented support for many of these patterns and others, and in my experience the problem is not at all the coding & testing involved: the real issue is the UI for inputting and for showing the status of predictions. Rather than providing so much flexibility, it works a lot better to offer a few pre-baked templates, and enable UI support for those.
Requesting market data
Predictions posted online tend to follow market trends, so the most popular cryptocurrencies get the most predictions, somewhat following the 80/20 Pareto principle. This means that, if we have 100 predictions and we evolve them every minute, we’re gonna be making a lot of identical requests to the exchange’s APIs. This is not just very inefficient but also unlikely to last long, because as the number of predictions grow, very soon the exchange’s APIs will ban our IPs and ask us to enhance our calm.
The simplest solution to this problem is to cache market responses. In theory, this makes perfect sense, since one wouldn’t expect historical market data to change. In practice, this is almost true, but one should be careful to consider some received data point “final”, since very recent data might be “still getting aggregated”, and exchanges do not clarify if a data point is final or not. A mitigation is to not consume very recent data points.
Note that the caching component is very valuable, but in a very small window of time. It’s not common to need to request old data, because most predictions are about future deadlines. Thus, it’s not necessary to build a full-fledged solution for caching.
Storing predictions and evolving them
Predictions are esentially state machines, and they have two parts: metadata (e.g. author, deadline, conditions), and state (e.g. last timestamp requested for each market pair, status of condition(s) that compose the prediction).
Only the state part evolves over time. On each evolution step, one needs to request the latest data points for the involved market pairs, re-evaluate the prediction condition(s) and possibly change the status of it to “correct”/“incorrect”.
Further, out of the database of predictions, only a subset evolves: the active predictions. However, the state part of all active predictions must be updated every time. This write pattern suggests using some in-memory layer before reaching the durable store to alleviate disk pressure and latency, although then if someone kicks the power cable progress is lost.
Of course, for a small project that is just starting up and where cost is a major concern, a batch update statement on a small Postgres instance is more than enough. In order to set up the project for growth, we can just hide the storage layer implementation details behind a simple interface.
Predictions tend to have a common deadline
End of year, end of month, or whenever a big event will take place (e.g. whenever the CPI is going to be announced, whenever the halving happens) are very common instants for predictions. This is absolutely fine in terms of evolving the predictions, but if one plans to trigger some actions like sending out notifications, instant hotspots could be problematic.
Possible mitigations are to buffer and aggregate notifications, or to cap the amount of notifications that can be sent in a given time period.
Takeaways from tracking predictions for the last few months
A key criticism for this project is that it is pointless to track what influencers say, because no one in their right mind should take their advice when they make their investment decisions. If you share this point of view (like me!), wouldn’t it be useful to be able to answer how often predictions become correct?
How often do predictions become correct?
Well, thanks to this project, I can answer that! Results have caveats (e.g. some influencers make more specific predictions than others, averaging results compares apples & oranges because some predictions are bolder than others), but they are definitely not meaningless. Insights will be vague, because the sample is less than a thousand predictions, and it simply hasn’t been that long since I started tracking them.
Here are the takeaways:
Predictions become correct reliably about 25% of the time.
Deadline matters: prediction correctness drops to 20% when deadline is 4 days or less in the future or more than a month, sweet spot being about two weeks.
80% of all predictions are made for a deadline earlier than or equal to a month in the future.
Some influencers are definitely more reliable than others.
I don’t want to be thought of as endorsing influencers and I also don’t want to talk without sufficient data, but I can say preliminarly that you should probably ignore specific predictions given by:
- rovercrc
- trader1sz
- profit8lue
And you could listen to (but don’t delegate your financial decisions!!!) specific predictions given by:
- CryptoCapo_
- IncomeSharks
- CredibleCrypto
There are plenty of others, but either they make vague predictions or don’t make enough to make statistically significant conclusions (in a 6 month timeframe).
Is there any more value out of this project?
Evidently, the current state of this project is of little relevance to people. Otherwise, the Twitter account would have more followers and my blogs about it would generate more buzz. Personally, I think anyone following a crypto influencer with the intention of following their advice can only benefit from an impartial, automated track-record for them, but this thought-process makes the assumption that human decisions always makes sense. This has been refuted, and it is really confusing to me.
However, in order to take this project to production I had to build many components that could be used or adapted for other interesting uses.
Evaluating paid subscriptions that offer “cryptocurrency signals”
Many individuals or anonymous companies offer a monthly subscription of “cryptocurrency signals”, which are esentially specific predictions. Those services routinely claim that 80%+ of their signals are profitable.
The only difference between signals and predictions is that signals are not “boolean”, in that they are not “Correct” or “Incorrect”, but instead they have a Profit Margin Ratio, that is, if you action them, you earn or lose a percentage of your investment.
Nobody has ever done a reliable, transparent evaluation of a Cryptocurrency Signal site. It would be too tricky to build the infrastructure necessary to run it. With the tools I’ve built, it would be very simple to do this.
Building datasets for data science experiments
If you’ve ever reviewed any articles that do research based on market data, you’ll quickly realise that it’s very rare to see any research aggregating data from different exchanges. There is Messari, but I initially implemented it and ended up scrapping it, as I couldn’t get reliable results.
The library I open sourced for reading market data, crypto-candles, is very efficient and has a very simple interface (it builds iterators), so I think it would be ideal for getting data for experiments.
In general, while there are very good freemium UIs for cryptocurrency data, most notably TradingView, there isn’t any good free API for getting market data across exchanges. crypto-candles solves this issue as a library you can import, or a CLI you can call.
Conclusion
I think that Crypto Predictions Tracker was a useful, free warning service for people thinking about following the advice of cryptocurrency influencers. But even if it’s not, I really enjoyed building its backend.
Unfortunately, Heroku shut down the dynos I was using to power the cron and the API (switched to Render which has a free plan with DB & Cron), and Twitter restricted their API access, so it got too cumbersome to support it. I think there’s value that can be repurposed in an eventual iteration.
Thanks for reading, and I hope you can benefit from the tools and services I created. Good luck!